Temporal: Hands-On com Agendamento de Workflows Self-Hosted
Por Fabio Douek
Ir para seção
- Visao Geral
- Arquitetura
- Setup
- Passo 1: Instalar a Temporal CLI e iniciar o dev server
- Passo 2: Clonar o repositorio companheiro
- Passo 3: Percorrer o codigo
- Testes
- Teste 1: Schedule por intervalo com overlap policy e jitter
- Teste 2: Schedule por calendario com timezone
- Teste 3: Pause, trigger, backfill, list
- Teste 4: Evoluir para docker-compose
- Limpeza
- Veredito
Explica (TLDR) como se eu fosse...
Imagine um relogio com lembretinhos pregados nele. Quando o relogio bate nove horas, ele avisa o seu robo ajudante para ir ver se o escorregador do parquinho ainda esta de pe. Se o escorregador estiver quebrado, o robo escreve um bilhete num caderninho para os adultos consertarem depois.
O legal e que o relogio guarda os lembretinhos, nao o robo. Entao se o robo tropeca e cai, o proximo robo pega o mesmo bilhete e termina a tarefa. E por isso que as pessoas escolhem esse relogio em vez do mais simples da cozinha: as tarefas nunca se perdem, mesmo quando algo da errado no meio do caminho.
Trate o Temporal como infraestrutura duravel para tarefas recorrentes. O proprio schedule e um registro do lado do servidor, separado do worker process que executa o trabalho. A responsabilidade muda de "o cron disparou" para "o workflow foi concluido", porque a plataforma rastreia toda tentativa, retry e resultado com trilha de auditoria.
A due diligence em um deployment self-hosted deve cobrir a escolha de persistencia (dev server in-memory versus Postgres), o catchup window padrao de um ano (que pode reexecutar runs perdidos apos longos periodos offline), e o fato de que o binario de dev e explicito sobre nao ser para producao. A licenca Apache 2.0 e permissiva, mas a pegada operacional e relevante e merece dimensionamento.
Pense no Temporal como um tratamento para uma condicao cronica comum: jobs agendados que falham silenciosamente porque o host travou no meio da execucao. O mecanismo e durable execution. Cada passo de um workflow agendado e registrado, entao um worker que falhou pode ser substituido e o trabalho retoma do ultimo passo concluido em vez de recomecar.
Efeitos colaterais a observar incluem overhead operacional de rodar um servidor mais um banco de dados, uma curva de aprendizado em torno das regras de determinismo no codigo do workflow, e um catchup window padrao de um ano que pode causar estouro apos longas indisponibilidades. Bons candidatos sao times que ja operam Postgres com tranquilidade; menos adequado para um cron job pontual em uma unica maquina.
Note o que muda quando o engenheiro de plantao deixa de ser paginado as 3 da manha porque um cron job morreu no meio. O trabalho se recupera sozinho, a tabela de incidentes conta a historia sem precisar de paginacao manual, e a manha de segunda comeca com evidencia em vez de trabalho de detetive.
O novo atrito e mais silencioso e merece ser nomeado. O time troca a legibilidade de um crontab de uma linha por um servidor, uma UI e uma curva de aprendizado. Alguns engenheiros sentem a perda do "consigo ler isso em cinco segundos". O trabalho de adocao e em parte tecnico e em parte sobre dar tempo ao time para confiar no novo formato do schedule antes de depender dele.
Trate Temporal Schedules como um metronomo que mantem o tempo mesmo quando a banda sai do palco. O intervalo bate a cada dois minutos, o calendario dispara as 09:00 nos dias uteis, e o jitter espalha as entradas para que dois musicos nao comecem o mesmo compasso no mesmo instante.
Onde ele se prova util e na recuperacao: se um musico cai no meio de uma frase, o metronomo lembra exatamente onde a parte estava, e o substituto retoma na batida certa. Overlap policies sao os sinais de mao do maestro: pular a proxima entrada, enfileirar uma, cancelar a anterior, ou deixar todos tocarem juntos.
A historia e o upgrade de "o cron disparou" para "o trabalho foi concluido". Faca self-host num laptop em menos de cinco minutos com um unico install via Homebrew, entregue um workflow Python recorrente com intervalos, cron strings, jitter e overlap policies, e evolua para uma stack com Postgres quando o time estiver pronto.
O posicionamento se encaixa em tres audiencias. Times queimados pelo peso operacional do Airflow, times que superaram as responsabilidades de overlap-locking do Celery Beat, e times rodando cron num laptop e se perguntando por que o job parou silenciosamente na terca passada. O antes-e-depois se escreve sozinho: um run perdido, depois um run-retomado-do-passo-quatro, com a trilha de auditoria anexada.

Visao Geral
Eu venho escrevendo cron jobs ha muitos anos e me virando bem. A maioria dos cron jobs e curta, idempotente, e o host e confiavel o suficiente para que “dispara a cada cinco minutos, funciona na maior parte das vezes” seja aceitavel. A historia desmorona no momento em que um job leva mais de um minuto ou conversa com um servico externo instavel. Quando voce precisa de um state file e logica de retry, ja esta dentro do espaco de problema de uma workflow engine.
Temporal e uma das varias workflow engines que valem o seu tempo, e a que estou cobrindo hoje. Outras virao em posts futuros. O argumento principal do Temporal e durable execution: voce escreve codigo, a plataforma registra cada passo, e se o seu worker process travar, o trabalho retoma de onde parou em vez de recomecar. Esse e o caso de uso de destaque, e a maior parte do conteudo sobre Temporal e sobre durabilidade de workflows.
Este post limita deliberadamente o escopo a agendamento. O Temporal expoe um objeto Schedule de primeira classe com intervalos, calendar specs, cron strings, timezone, jitter, overlap policy, backfill, pause e trigger ad-hoc, nada disso voce precisa amarrar manualmente. Durable execution ainda se aplica por baixo (cada run agendado e um workflow), mas o foco aqui e na superficie de agendamento.
Arquitetura
Antes de qualquer codigo, a topologia. O Temporal nao e uma library que voce importa no seu worker; e um servidor com o qual voce conversa via gRPC. O schedule vive no servidor. Seu codigo vive em um worker process que faz polling de uma task queue.

Como um run agendado flui pelo diagrama:
- O schedule dispara do lado do servidor. E um registro no Temporal Server, nao um
while True: sleepno seu codigo. Ele bate independentemente do seu worker estar vivo ou nao. - O servidor inicia um Workflow Execution e enfileira a primeira task na task queue nomeada (neste post,
health-check-queue). - Seu worker Python faz polling daquela task queue via gRPC na
:7233, pega a task, e executa o workflow e as activities que voce definiu. - Cada passo e registrado na persistencia (SQLite para
temporal server start-dev, Postgres na stack docker-compose). Mate o worker no meio do run, suba um novo, e o trabalho retoma do ultimo passo concluido. - A Web UI le do servidor:
:8233em dev,:8080em compose. Nada no seu codigo Python muda entre os dois.
temporal server start-dev e a stack docker-compose. As duas stacks sao drop-in replacements em todo o resto, mas a URL da UI muda. Eu ja perdi uma quantidade vergonhosa de tempo com isso.
Setup
Estou rodando macOS em Apple Silicon. O post foi escrito para macOS, mas tudo funciona em Linux ou Windows com pequenas trocas de comando: principalmente as linhas brew install, que viram apt/dnf/pacman no Linux ou o script instalador da Temporal CLI no Windows. O codigo Python, os targets do Makefile e a stack docker-compose sao identicos entre plataformas.
Passo 1: Instalar a Temporal CLI e iniciar o dev server
A CLI e um install do Homebrew. O dev server e o mesmo binario, em um modo que sobe uma stack Temporal completa com a Web UI ja embutida:
brew install temporal
temporal server start-dev \
--db-filename ./temporal.db \
--ui-port 8233Apos o Passo 2 (clone), make dev roda o mesmo comando de dentro do diretorio do projeto.
Essa e a instalacao local inteira. --db-filename escreve o estado em um arquivo SQLite para que ele sobreviva a restarts; sem isso, voce fica com um banco in-memory e seus schedules somem no Ctrl-C. O endpoint gRPC do frontend escuta em localhost:7233, a Web UI em http://localhost:8233, e o namespace default ja e criado para voce.
Verifique com a mesma CLI:
temporal operator namespace list
# default
temporal workflow list
# (empty)Passo 2: Clonar o repositorio companheiro
O repositorio companheiro do my2cents.ai contem o projeto completo. Clone, entre no diretorio do projeto e instale as dependencias:
# 1. Clone the samples repository
git clone https://github.com/fabiodouek/my2centsai-blog-samples.git
# 2. Change into the project directory
cd my2centsai-blog-samples/temporal-scheduling-quickstart
# 3. Install uv if you do not already have it
brew install uv
# 4. Install Python 3.12 and the project's pinned dependencies
uv python install 3.12
uv syncO que voce vai encontrar dentro do projeto:
temporal-scheduling-quickstart/
├── pyproject.toml # Python 3.12, three deps, hatchling build
├── Makefile # one-command dev / worker / schedule / clean
├── docker-compose.yml # Postgres-backed stack for the second track
├── README.md
├── .env.example # TEMPORAL_ADDRESS, TASK_QUEUE, DB_PATH
└── src/
├── config.py # env-driven config
├── targets.py # the httpbin.org targets to probe
├── storage.py # SQLite schema and insert helper
├── activities.py # probe_endpoint + record_incident
├── workflows.py # HealthCheckWorkflow
├── worker.py # registers workflow + activities
└── schedules/
├── create_interval.py # every 2 min, jitter, overlap=SKIP
├── create_cron.py # weekday 09:00 America/New_York
├── pause_trigger.py # pause / unpause / trigger
├── backfill.py # backfill the last 30 minutes
├── list_describe.py # list / describe schedules
└── delete_all.py # drop both schedulesmake dev em um terminal (sobe o Temporal dev server), make worker em outro (roda o worker Python), make schedule em um terceiro (cria o schedule de 2 em 2 minutos). Depois abra http://localhost:8233. O passo a passo abaixo explica o que cada arquivo faz.
Passo 3: Percorrer o codigo
O workflow sonda uma lista de targets HTTP. Cada sondagem e uma activity (entao retries e timeouts sao a nivel de framework), e uma sondagem que falha registra uma linha de incidente no SQLite (tambem via activity, porque codigo de workflow nao pode fazer I/O diretamente). Os quatro arquivos que importam ficam em src/.
Abra src/targets.py, a lista a sondar:
from dataclasses import dataclass
@dataclass
class Target:
name: str
url: str
expected_status: int
timeout_seconds: float = 5.0
TARGETS: list[Target] = [
Target(
name="httpbin-ok",
url="https://httpbin.org/status/200",
expected_status=200,
),
Target(
name="httpbin-flaky",
url="https://httpbin.org/status/500",
expected_status=200,
),
Target(
name="httpbin-slow",
url="https://httpbin.org/delay/2",
expected_status=200,
timeout_seconds=4.0,
),
]https://httpbin.org/status/500 e o target deliberadamente quebrado. E o que o schedule vai capturar e registrar como incidente. httpbin-slow existe para exercitar o start_to_close_timeout das activities.
Abra src/activities.py, as duas activities:
import time
from dataclasses import dataclass
import httpx
from temporalio import activity
from temporalio.exceptions import ApplicationError
from .storage import init_db, insert_incident
from .targets import Target
@dataclass
class ProbeResult:
target_name: str
target_url: str
status_code: int
elapsed_ms: int
@activity.defn
async def probe_endpoint(target: Target) -> ProbeResult:
start = time.perf_counter()
async with httpx.AsyncClient(timeout=target.timeout_seconds) as http:
resp = await http.get(target.url)
elapsed_ms = int((time.perf_counter() - start) * 1000)
if resp.status_code != target.expected_status:
raise ApplicationError(
f"unexpected status {resp.status_code} from {target.url}",
type="UnexpectedStatus",
)
return ProbeResult(target.name, target.url, resp.status_code, elapsed_ms)
@activity.defn
async def record_incident(
target_name, target_url, status_code, error, elapsed_ms,
) -> None:
await init_db()
await insert_incident(
target_name, target_url, status_code, error, elapsed_ms,
)Abra src/workflows.py. O workflow itera sobre os targets, faz retry de cada sondagem com backoff exponencial, e registra incidentes para falhas terminais. O proprio workflow nunca lanca excecao, entao o schedule continua disparando mesmo quando um target esta permanentemente fora do ar:
from datetime import timedelta
from temporalio import workflow
from temporalio.common import RetryPolicy
with workflow.unsafe.imports_passed_through():
from .activities import probe_endpoint, record_incident
from .targets import TARGETS
@workflow.defn
class HealthCheckWorkflow:
@workflow.run
async def run(self) -> dict[str, str]:
retry_policy = RetryPolicy(
initial_interval=timedelta(seconds=1),
backoff_coefficient=2.0,
maximum_interval=timedelta(seconds=10),
maximum_attempts=3,
non_retryable_error_types=["UnexpectedStatus"],
)
results: dict[str, str] = {}
for target in TARGETS:
try:
outcome = await workflow.execute_activity(
probe_endpoint,
target,
start_to_close_timeout=timedelta(seconds=15),
retry_policy=retry_policy,
)
results[target.name] = f"ok status={outcome.status_code}"
except Exception as e:
workflow.logger.warning(f"{target.name} failed: {e}")
await workflow.execute_activity(
record_incident,
args=[target.name, target.url, None, str(e), 0],
start_to_close_timeout=timedelta(seconds=10),
)
results[target.name] = f"incident: {e}"
return resultsUma nota sobre non_retryable_error_types=["UnexpectedStatus"]: o Temporal vai retentar uma activity ate atingir maximum_attempts, exceto se o type do ApplicationError lancado bater com uma string nao-retentavel. Nao queremos retentar um 500 tres vezes: o target esta quebrado, registre e siga em frente. Erros de rede (timeouts, falhas de DNS, connection resets) lancam tipos de erro diferentes e sao retentados.
Abra src/worker.py, e chato e voce quer que seja:
import asyncio
from temporalio.client import Client
from temporalio.worker import Worker
from .activities import probe_endpoint, record_incident
from .config import TASK_QUEUE, TEMPORAL_ADDRESS, TEMPORAL_NAMESPACE
from .workflows import HealthCheckWorkflow
async def main() -> None:
client = await Client.connect(TEMPORAL_ADDRESS, namespace=TEMPORAL_NAMESPACE)
worker = Worker(
client,
task_queue=TASK_QUEUE,
workflows=[HealthCheckWorkflow],
activities=[probe_endpoint, record_incident],
)
await worker.run()
if __name__ == "__main__":
asyncio.run(main())Inicie o worker em um segundo terminal (de dentro de temporal-scheduling-quickstart/):
uv run python -m src.worker
# or: make workerVoce agora tem um Temporal server, um worker Python e zero schedules. Hora de adicionar alguns.
Testes
Eu testei quatro coisas, nesta ordem: um schedule por intervalo com overlap policy e jitter; um schedule por calendario com timezone; pause / trigger / backfill / list contra um schedule ativo; e a evolucao para a stack docker-compose com Postgres.
Teste 1: Schedule por intervalo com overlap policy e jitter
O schedule por intervalo e o cavalo de batalha entediante e duravel que a maioria dos times quer. A cada dois minutos, com dez segundos de jitter para que schedules concorrentes no mesmo cluster nao disparem todos no mesmo tick de relogio. Abra src/schedules/create_interval.py:
# src/schedules/create_interval.py
import asyncio
from datetime import timedelta
from temporalio.client import (
Client,
Schedule,
ScheduleActionStartWorkflow,
ScheduleIntervalSpec,
ScheduleOverlapPolicy,
SchedulePolicy,
ScheduleSpec,
ScheduleState,
)
from ..config import (
INTERVAL_SCHEDULE_ID, TASK_QUEUE, TEMPORAL_ADDRESS,
TEMPORAL_NAMESPACE, WORKFLOW_ID_PREFIX,
)
from ..workflows import HealthCheckWorkflow
async def main() -> None:
client = await Client.connect(TEMPORAL_ADDRESS, namespace=TEMPORAL_NAMESPACE)
schedule = Schedule(
action=ScheduleActionStartWorkflow(
HealthCheckWorkflow.run,
id=f"{WORKFLOW_ID_PREFIX}-interval",
task_queue=TASK_QUEUE,
),
spec=ScheduleSpec(
intervals=[ScheduleIntervalSpec(every=timedelta(minutes=2))],
jitter=timedelta(seconds=10),
),
policy=SchedulePolicy(
overlap=ScheduleOverlapPolicy.SKIP,
catchup_window=timedelta(minutes=10),
),
state=ScheduleState(note="Health check every 2 minutes with 10s jitter."),
)
await client.create_schedule(INTERVAL_SCHEDULE_ID, schedule)
if __name__ == "__main__":
asyncio.run(main())Rode (o arquivo ja existe no repositorio clonado):
uv run python -m src.schedules.create_interval
# or: make schedule
# created schedule: health-check-intervalAbra http://localhost:8233/namespaces/default/schedules e o schedule aparece com seu proximo horario de execucao:
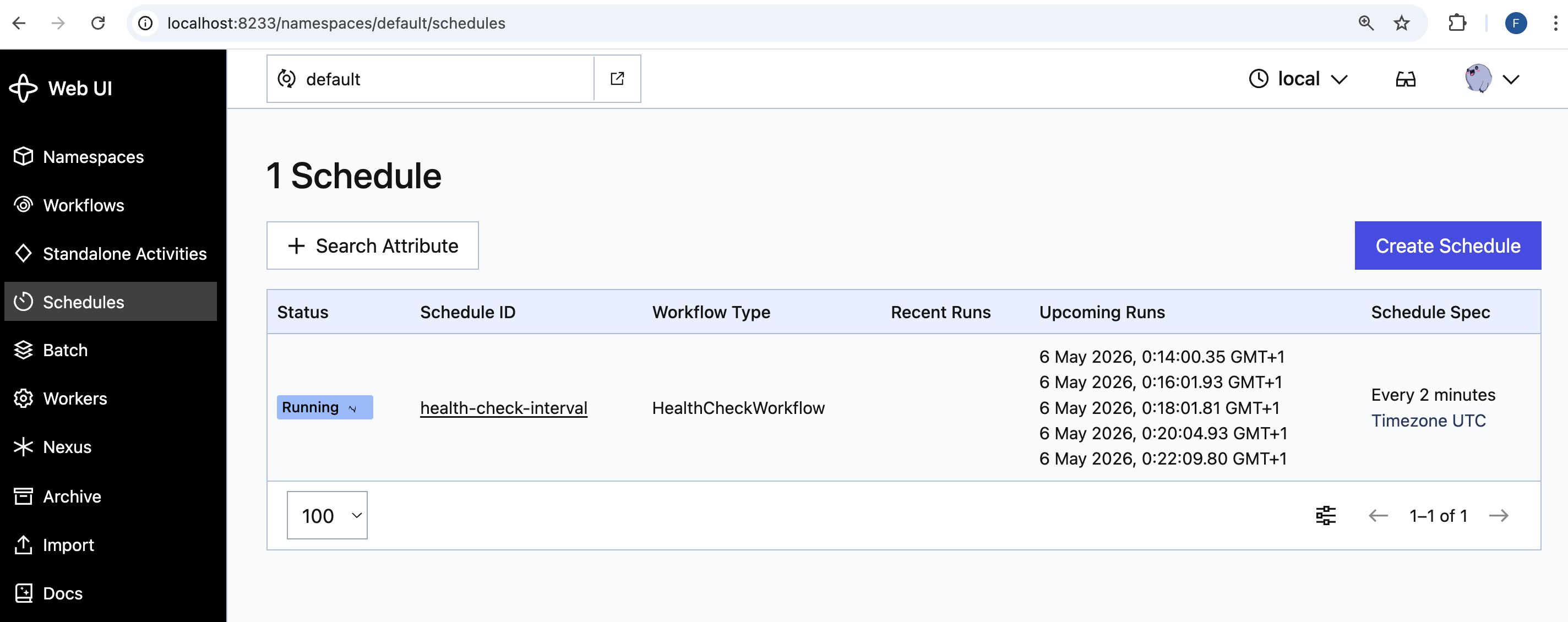
Em quatro minutos os dois primeiros runs aparecem. Cada run aparece como um workflow execution com o mesmo prefixo de workflow ID. Clique em View All Runs na pagina de detalhe do schedule para ver o historico completo. A lista esta ordenada do mais novo para o mais antigo, entao os dois primeiros runs ficam embaixo:
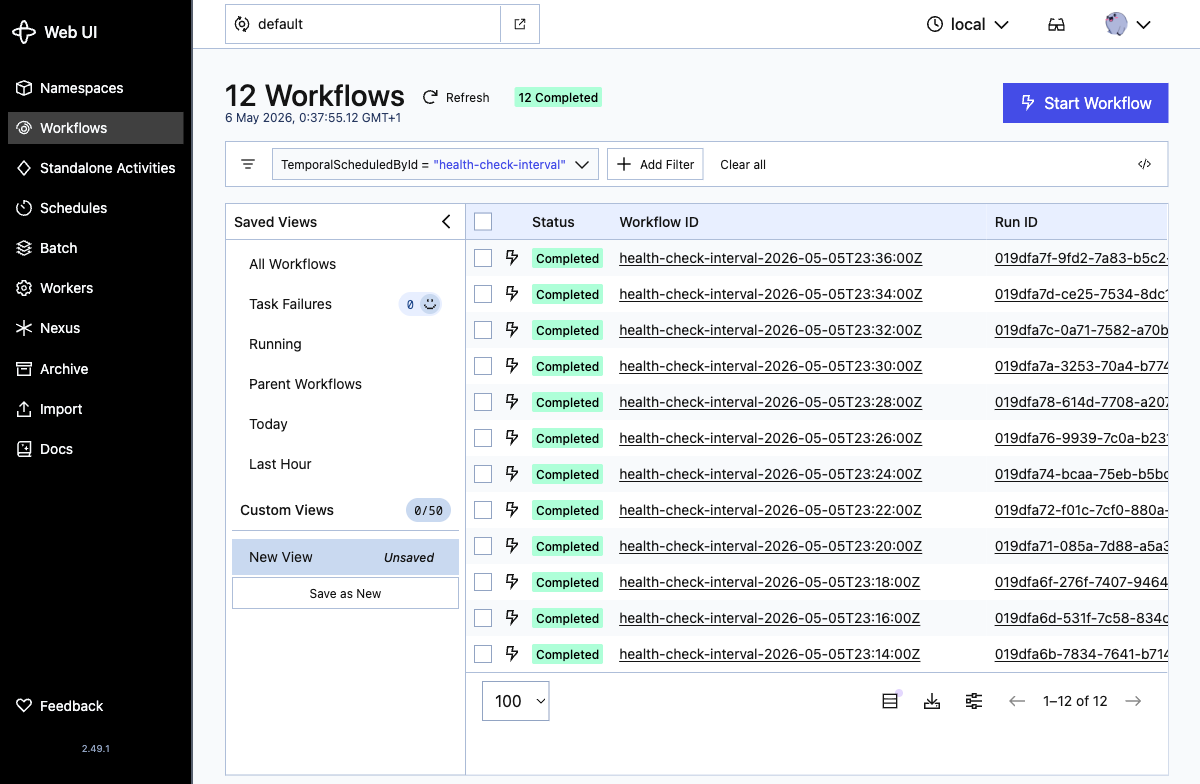
Olhando dentro de um run, o resultado do workflow mostra o desfecho por target: os dois targets saudaveis retornam ok, e httpbin-flaky registra um incidente depois que o Temporal esgota o orcamento de retry da activity:
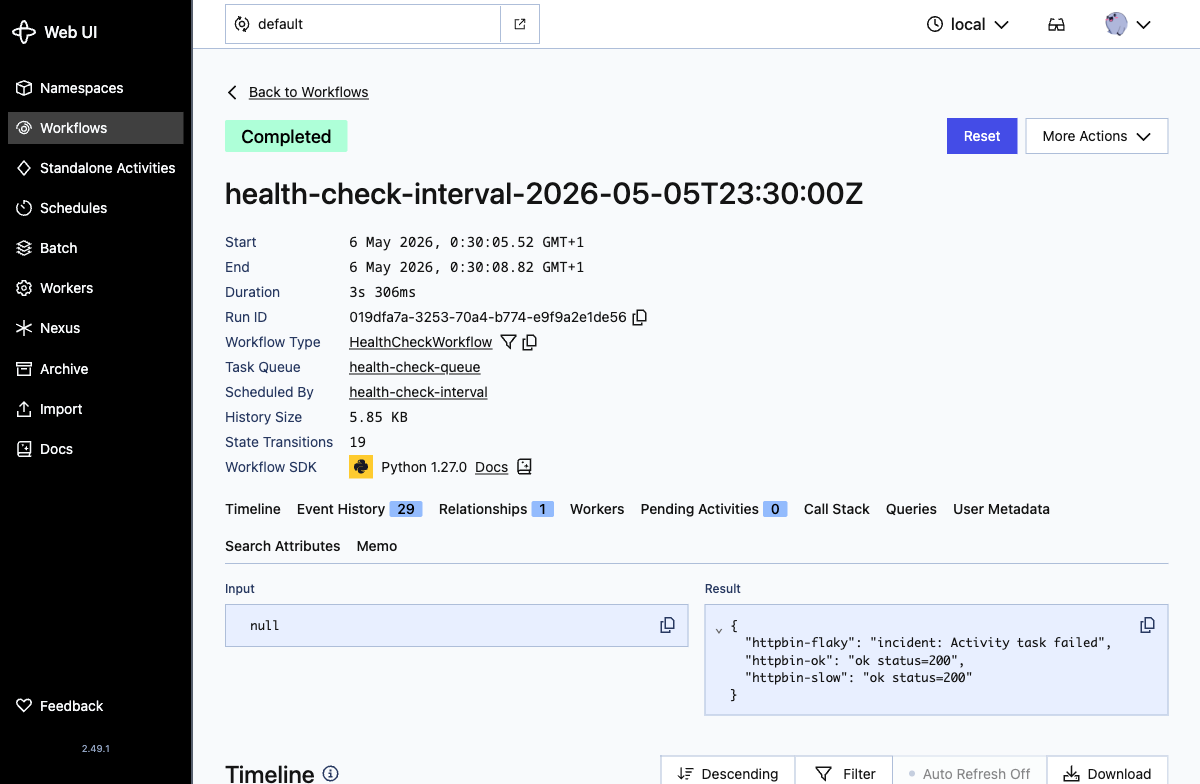
Aquela linha "httpbin-flaky": "incident: Activity task failed" corresponde a uma linha gravada em incidents.db pela activity record_incident.
Os dois botoes deste snippet que importam:
SchedulePolicy.overlap=ScheduleOverlapPolicy.SKIP: se o run anterior ainda esta rodando no proximo tick, pule o proximo tick. Seis valores estao disponiveis:SKIP,BUFFER_ONE,BUFFER_ALL,CANCEL_OTHER,TERMINATE_OTHER,ALLOW_ALL.SKIPe o default certo para “seria bom rodar a cada dois minutos mas nunca dois ao mesmo tempo”.catchup_window=timedelta(minutes=10): se o servidor ficou inacessivel por dez minutos e perdeu cinco runs, dispare apenas o mais recente quando voltar. O default se voce nao setar e um ano, o que significa que uma longa indisponibilidade do servidor pode causar estouro de milhares de replays na hora da recuperacao. Defina isso explicitamente. Sempre.
Teste 2: Schedule por calendario com timezone
O schedule por intervalo e certo para “a cada dois minutos”. O schedule por calendario e certo para “todo dia util as 09:00 horario de Nova York”. Calendar specs usam ScheduleRange(start, end, step) para cada campo do calendario. Abra src/schedules/create_cron.py:
# src/schedules/create_cron.py (excerpt)
from temporalio.client import (
ScheduleCalendarSpec, ScheduleRange, ScheduleSpec, SchedulePolicy,
ScheduleOverlapPolicy,
)
weekday_9am = ScheduleCalendarSpec(
hour=(ScheduleRange(start=9),),
minute=(ScheduleRange(start=0),),
day_of_week=(ScheduleRange(start=1, end=5),), # Mon..Fri
comment="Weekdays 09:00 America/New_York",
)
schedule = Schedule(
action=ScheduleActionStartWorkflow(
HealthCheckWorkflow.run,
id="health-check-cron",
task_queue=TASK_QUEUE,
),
spec=ScheduleSpec(
calendars=[weekday_9am],
time_zone_name="America/New_York",
),
policy=SchedulePolicy(overlap=ScheduleOverlapPolicy.BUFFER_ONE),
state=ScheduleState(note="Weekday morning health check."),
)Rode da mesma forma que o Teste 1:
uv run python -m src.schedules.create_cron
# or: make cron
# created schedule: health-check-cronAbra a pagina de detalhe do schedule health-check-cron. O painel Upcoming Runs prova que o calendar spec e o timezone estao conectados: cada entrada esta as 09:00 America/New_York, traduzida pela Web UI para o seu timezone local, e a lista pula da sexta 8 de maio direto para segunda 11 de maio, ignorando o fim de semana:
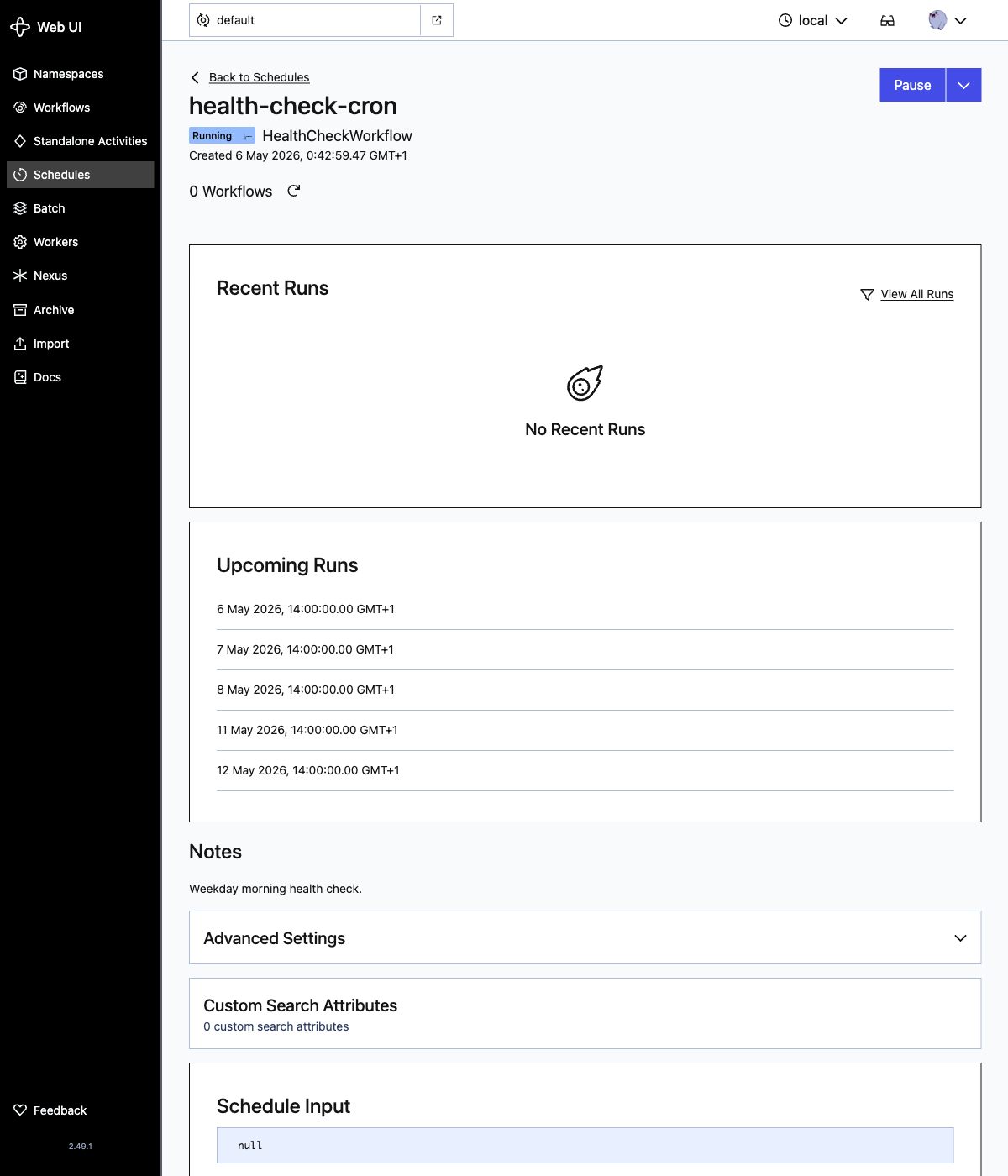
Se voce preferir uma string crontab familiar, troque calendars=[weekday_9am] por cron_expressions=["0 9 * * MON-FRI"]. Ambos funcionam. O formato calendar e mais legivel para expressoes nao triviais e o formato cron e mais curto para as faceis.
Teste 3: Pause, trigger, backfill, list
Esse foi o teste que me virou de “Temporal e interessante” para “estou substituindo meu cron”. Nenhuma dessas operacoes existe no cron. Todas elas sao uma chamada Python. Abra src/schedules/pause_trigger.py:
# src/schedules/pause_trigger.py (excerpt)
handle = client.get_schedule_handle("health-check-interval")
await handle.pause(note="Maintenance window")
await handle.unpause(note="Resuming")
await handle.trigger(overlap=ScheduleOverlapPolicy.ALLOW_ALL)Backfill e a feature matadora. “O schedule ficou pausado por uma hora, por favor rode todos os runs que perdemos.” Abra src/schedules/backfill.py:
# src/schedules/backfill.py
from datetime import datetime, timedelta, timezone
from temporalio.client import ScheduleBackfill, ScheduleOverlapPolicy
handle = client.get_schedule_handle("health-check-interval")
now = datetime.now(timezone.utc)
await handle.backfill(
ScheduleBackfill(
start_at=now - timedelta(minutes=30),
end_at=now - timedelta(minutes=1),
overlap=ScheduleOverlapPolicy.ALLOW_ALL,
),
)overlap=ALLOW_ALL aqui significa “dispare todos os runs perdidos concorrentemente”. Escolha BUFFER_ALL se voce quer que sejam sequenciais.
Comece pausando o schedule e descrevendo:
uv run python -m src.schedules.pause_trigger pause
# or: make pause
uv run python -m src.schedules.list_describe describe
# or: make describe
# id: health-check-interval
# note: Paused via pause_trigger.py
# paused: True
# num_actions: 19
# num_actions_skipped_overlap:0
# running_actions: 0
# last_action_started_at: 2026-05-05 23:50:07.151203+00:00
# last_action_scheduled_at: 2026-05-05 23:50:07.127000+00:00
# next_action_at: 2026-05-05 23:54:02.613000+00:00A linha paused: True mais o next_action_at no futuro sao a prova: o schedule ainda tem um relogio de tick ativo, mas esta bloqueado pelo pause. Despausar destrava o gate sem resetar nada.
A pagina de lista de Schedules tambem mostra o estado de pause: health-check-interval carrega um badge amarelo de Paused enquanto health-check-cron mantem Running:
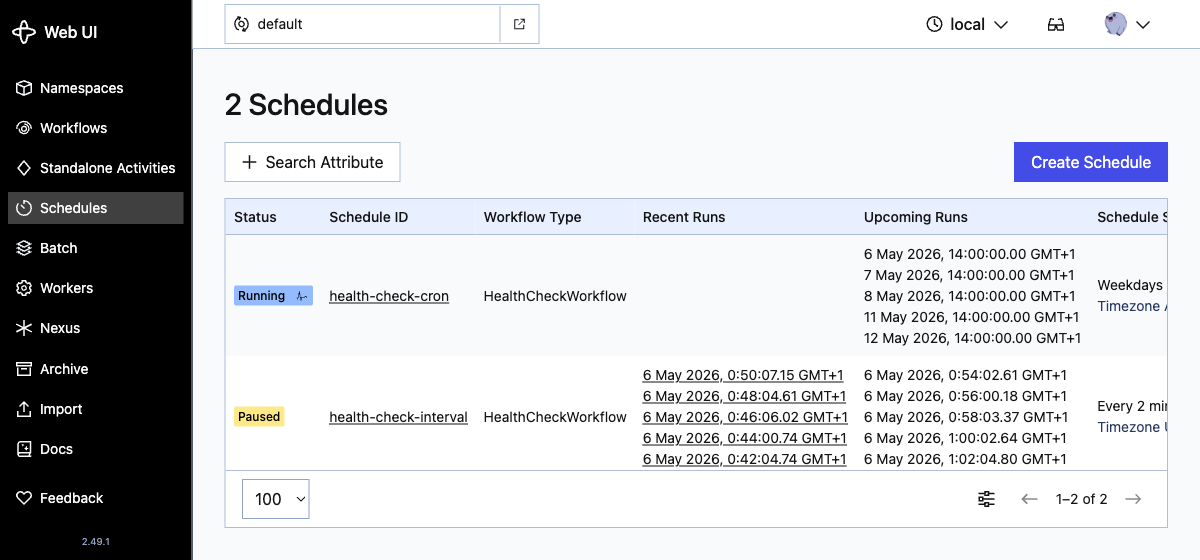
Agora exercite o resto do ciclo de vida. Despause para destravar o gate, faca backfill para disparar os runs que voce perdeu, e dispare um run extra ad-hoc:
uv run python -m src.schedules.pause_trigger unpause
# or: make unpause
uv run python -m src.schedules.backfill
# or: make backfill
uv run python -m src.schedules.pause_trigger trigger
# or: make triggerCada comando leva menos de um segundo. A Web UI reflete cada mudanca em tempo real. Cron, em contraste, nao tem nocao de nada disso.
Teste 4: Evoluir para docker-compose
O dev server e otimo para prototipagem mas e um processo so e SQLite. Eventualmente voce vai querer Postgres e um servidor com restart separado. O caminho e a stack docker-compose.
O repositorio companheiro do my2cents.ai inclui um docker-compose.yml enxuto:
services:
postgresql:
image: postgres:16
environment:
POSTGRES_PASSWORD: temporal
POSTGRES_USER: temporal
ports: ["5432:5432"]
volumes: ["postgres-data:/var/lib/postgresql/data"]
temporal:
image: temporalio/auto-setup:1.27
depends_on: [postgresql]
environment:
DB: postgres12
DB_PORT: 5432
POSTGRES_USER: temporal
POSTGRES_PWD: temporal
POSTGRES_SEEDS: postgresql
ports: ["7233:7233"]
temporal-ui:
image: temporalio/ui:2.40.1
depends_on: [temporal]
environment:
TEMPORAL_ADDRESS: temporal:7233
ports: ["8080:8080"]
volumes:
postgres-data:Pare o dev server (Ctrl-C), suba a stack, e o mesmo worker Python, mesmo endereco localhost:7233, conecta sem mudancas:
make compose-up[+] up 60/60
✔ Image postgres:16 Pulled 7.0s
✔ Image temporalio/auto-setup:1.27 Pulled 6.8s
✔ Image temporalio/ui:2.40.1 Pulled 6.0s
✔ Network temporal-scheduling-quickstart_default Created 0.0s
✔ Volume temporal-scheduling-quickstart_postgres-data Created 0.0s
✔ Container temporal-scheduling-quickstart-postgresql-1 Started 0.6s
✔ Container temporal-scheduling-quickstart-temporal-1 Started 0.3s
✔ Container temporal-scheduling-quickstart-temporal-ui-1 Started 0.3sDepois aponte um worker para ela e recrie o schedule:
make worker # in another terminal
make schedule
open http://localhost:8080 # UI is on 8080 here, not 8233O schedule, o codigo do workflow, o codigo das activities e o codigo do worker sao byte-a-byte identicos ao que rodou contra o dev server. Esse e o ganho arquitetural: dev e producao self-hosted sao o mesmo sistema, apenas persistidos de forma diferente.
Self-hosting de nivel producao e uma conversa maior: TLS, namespaces, advanced visibility via Elasticsearch, archival, replicacao multi-cluster. O self-hosted guide e a proxima leitura certa. Para uma demo de um laptop so, os tres servicos do compose acima sao suficientes.
Limpeza
Pare o dev server com Ctrl-C no terminal rodando make dev. Se voce subiu a stack docker-compose, derrube e remova o volume do Postgres para nao deixar um banco velho montado:
make delete # drops the schedules from the cluster
make compose-down # stops compose and deletes the postgres volume
make clean # removes incidents.db and temporal.dbSchedules sao registros do lado do servidor. Se voce nao deleta antes de deletar o banco, eles somem com o banco. Se voce mantem o banco e sobe um worker novo, eles voltam a disparar imediatamente. Seja deliberado sobre qual dos dois voce quer.
Veredito
Uma engine de durable execution prova seu peso especificamente em workloads de AI. Chamadas a LLM sao lentas, caras e rate-limited; fluxos agenticos encadeiam dez ou vinte delas; jobs de inferencia em batch podem rodar por horas. Um scheduler estilo cron que perde um run em andamento forca o proximo tick a refazer o gasto, e logica ad-hoc de retry agrava a conta toda vez que erra um pouquinho. O Temporal move “o trabalho foi concluido, com quais passos ja pagos” para dentro da plataforma: cada tool call, cada retry, cada sleep longo e um checkpoint, e um worker que travou retoma do ultimo em vez de recomecar a cadeia. Esse e um formato de garantia diferente de “o cron disparou as 03:00”.