AWS DevOps Agent: Hands-On com Análise Automatizada de Causa Raiz
Por Fabio Douek

Visão Geral
AWS DevOps Agent é um agente de operações com IA que investiga incidentes, identifica causas raiz e recomenda correções. A AWS o chama de “frontier agent” para excelência operacional. Ele ficou disponível em 31 de março de 2026, após um preview público que começou no re:Invent 2025 em dezembro. É um produto separado e mais avançado que o Amazon CloudWatch Investigations gratuito, lançado no início de 2025.
A proposta é direta: em vez de um SRE investigar manualmente logs do CloudWatch, correlacionar métricas entre serviços e verificar deploys recentes, o agente faz isso de forma autônoma. Ele constrói um grafo de topologia dos seus recursos, conecta-se ao seu stack de observabilidade (CloudWatch, Datadog, Dynatrace, New Relic, Splunk, Grafana), importa dados de CI/CD do GitHub ou GitLab, e segue a trilha do sintoma até a causa raiz. Ele publica suas descobertas no Slack, ServiceNow ou PagerDuty, e fornece passos específicos de mitigação. Ele não faz auto-remediação. Um humano ainda precisa aprovar e executar a correção.
Neste post, eu coloquei o DevOps Agent em um teste prático contra um stack serverless. Eu fiz deploy de uma API CRUD simples com Lambda + API Gateway + DynamoDB usando CloudFormation, escrevi um script de chaos engineering para simular uma falha realista de produção (starvation de capacidade do DynamoDB), e deixei o DevOps Agent investigar a cascata de falhas. O objetivo: ver se o agente consegue rastrear uma cadeia de erros 5xx do API Gateway, passando por falhas do Lambda até uma mudança de configuração do DynamoDB, medir quanto tempo a investigação leva e calcular o custo real. Eu percorro todo o setup, a injeção de caos, os resultados da investigação e se a ferramenta entrega o que promete.
Setup
Configurar o DevOps Agent leva cerca de 15 minutos. Aqui está o processo passo a passo.
Pré-requisitos
- Uma conta AWS em uma região suportada. Eu usei
us-east-1. As seis regiões GA são: US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt) e Europe (Ireland). - Permissões IAM para criar service-linked roles e gerenciar ações
aidevops:*.
Passo 1: Habilitar o DevOps Agent
Navegue até o console do AWS DevOps Agent e clique em Begin Setup, que levará você à página de criação do Agent Space.
Passo 2: Criar um Agent Space
Um Agent Space é o conceito organizacional central. Ele define o que o agente pode acessar: quais contas AWS, quais integrações de terceiros e quem pode interagir com as investigações.
Clique em Create Agent Space e preencha:
- Agent Space Name: Algo descritivo. Eu usei
serverless-demo. - Description (opcional): Uma frase sobre o que este space monitora.
- Agent response language: O idioma para as descobertas e recomendações geradas. O padrão é inglês (US).
- AWS resource access: Em “Configure primary account role”, escolha “Auto-create a new DevOps Agent role” (selecionado por padrão). Isso cria uma role chamada
DevOpsAgentRole-AgentSpace-<id>com acesso somente leitura a mais de 150 serviços AWS. - Enable web app: Na parte inferior, habilite o web app e crie automaticamente uma role DevOps Squad para acesso de operadores.
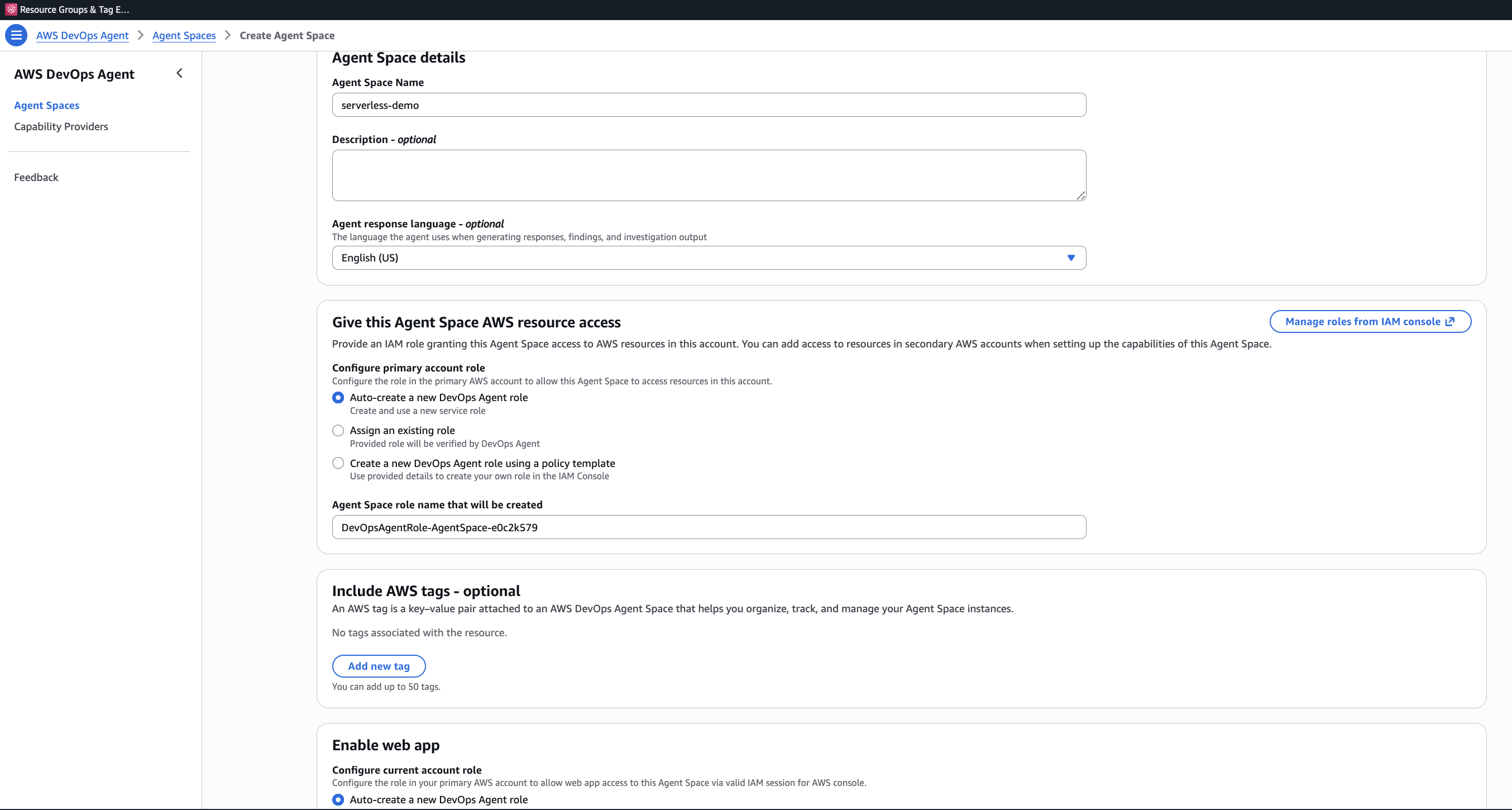
A IAM role usa o namespace aidevops:* e confia no service principal aidevops.amazonaws.com. Ela é somente leitura por design. O agente não pode modificar seus recursos.
Passo 3: Configuração do Agent Space
Uma vez criado o Agent Space, você chega ao seu dashboard. O agente imediatamente começa a mapear sua infraestrutura. No meu caso, ele encontrou 70 relacionamentos em minutos, descobrindo recursos e como eles se conectam entre si.
A aba Configuration permite configurar destinos de entrega de logs e ajustar o comportamento do agente. A aba Capabilities é onde você adiciona integrações de terceiros. Para esta demo, CloudWatch é a única integração necessária e já vem habilitada por padrão.
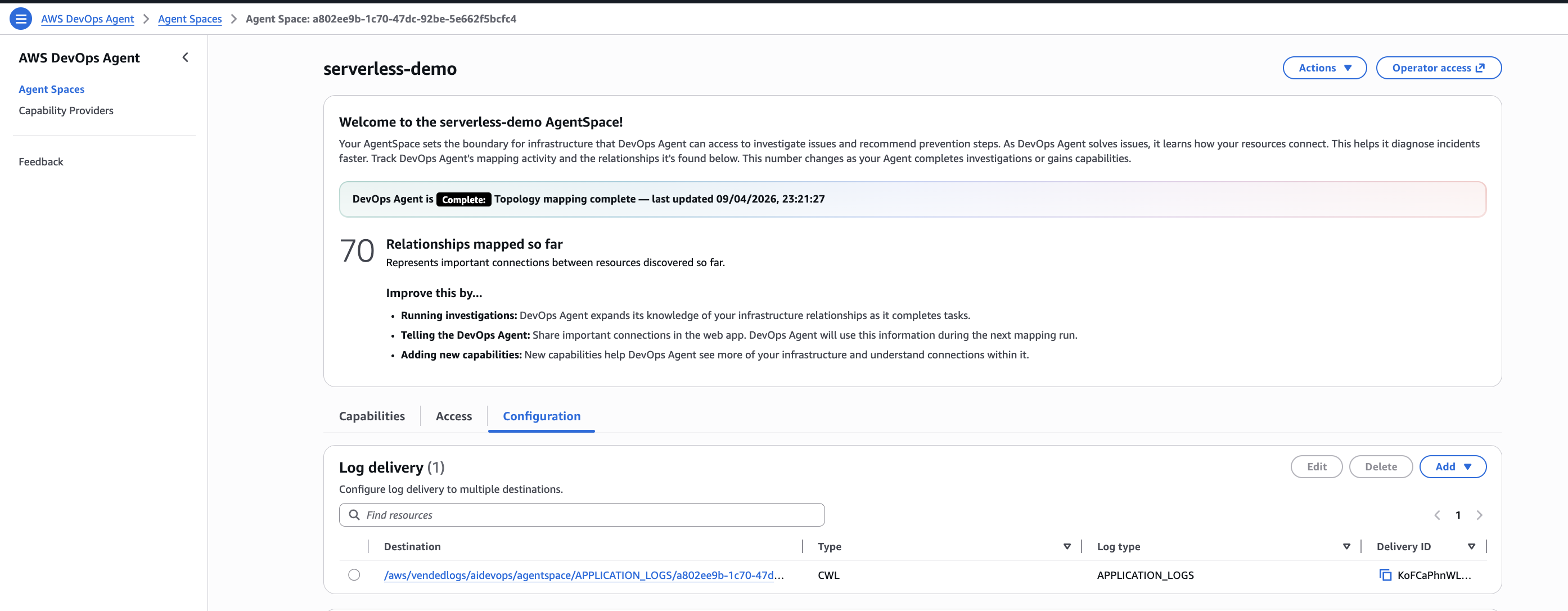
Integrações opcionais que você pode adicionar em Capabilities:
- Secondary Sources: Outras contas AWS, assinatura Azure
- Observability: Datadog, Dynatrace, Grafana, New Relic, Splunk
- CI/CD: GitHub, GitLab, Azure DevOps
- Ticketing/Chat: Slack, ServiceNow, PagerDuty
- Custom: Qualquer sistema via servidores MCP (Model Context Protocol)
Passo 4: Tagueie Seus Recursos
O DevOps Agent descobre seus recursos através de dois mecanismos: descoberta de stacks CloudFormation e tags de recursos. Para recursos implantados fora do CloudFormation, adicione a tag devopsagent=true para torná-los visíveis.
O template CloudFormation nesta demo já inclui tags em todos os recursos:
Tags:
- Key: devopsagent
Value: "true"
- Key: Project
Value: !Ref ProjectNameIsso é tudo para o setup. O agente agora está monitorando sua conta.
A Demo: Debugando uma Falha Serverless
Aqui está o plano: fazer deploy de uma API CRUD simples, quebrá-la ao privar o DynamoDB de capacidade, e ver se o DevOps Agent consegue rastrear a falha em cascata até a causa raiz.
Arquitetura
Client --> API Gateway --> Lambda --> DynamoDB
|
CloudWatch Alarms <-- CloudWatch Metrics
|
AWS DevOps Agent (investigates)O stack inclui um dashboard CloudWatch e três alarmes que serão acionados durante o experimento de caos:
- Lambda errors: Aciona quando a função gera 5+ erros em um minuto
- API Gateway 5xx: Aciona quando 5+ erros de servidor ocorrem em um minuto
- DynamoDB throttles: Aciona em qualquer evento de throttle de escrita
Fazendo Deploy do Workload
Clone o repositório complementar e faça o deploy:
git clone https://github.com/fabiodouek/my2centsai-blog-samples.git
cd my2centsai-blog-samples/aws-devops-agent-demo
chmod +x scripts/*.sh chaos/*.sh
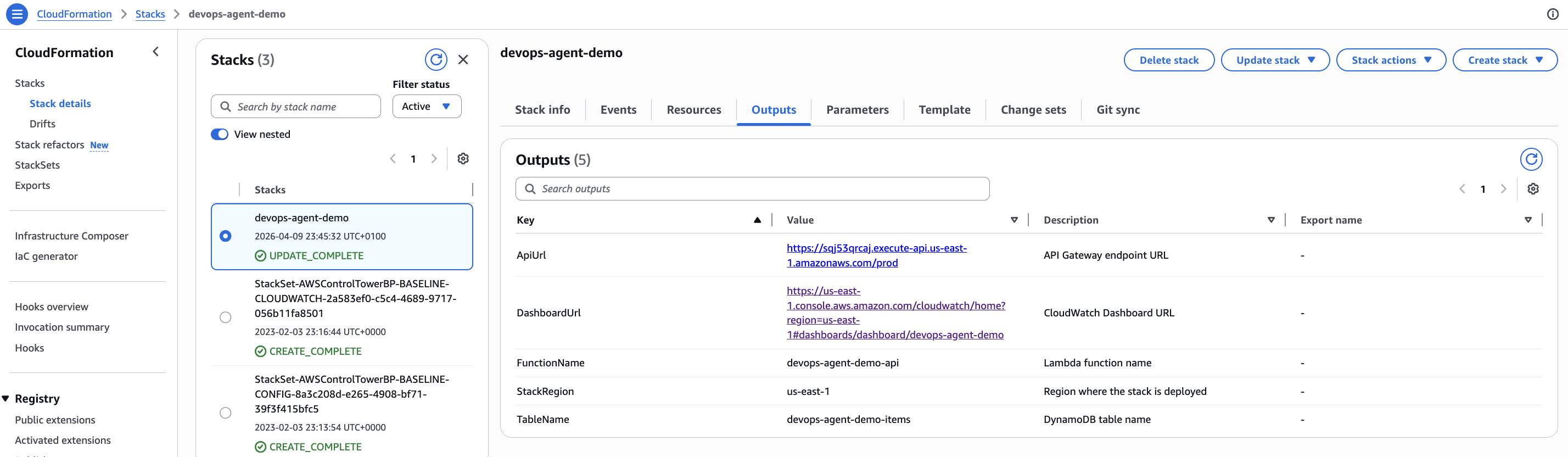
./scripts/deploy.sh devops-agent-demo us-east-1O stack CloudFormation cria:
- Uma tabela DynamoDB (
devops-agent-demo-items) em modo de cobrança on-demand - Uma função Lambda (
devops-agent-demo-api) rodando Python 3.12 - Uma API REST no API Gateway com um endpoint CRUD
/items - Um dashboard CloudWatch com status de alarmes e gráficos de métricas
- Três alarmes CloudWatch monitorando erros
O deploy leva cerca de 2 minutos. A saída fornece a URL da API:
Testando a API
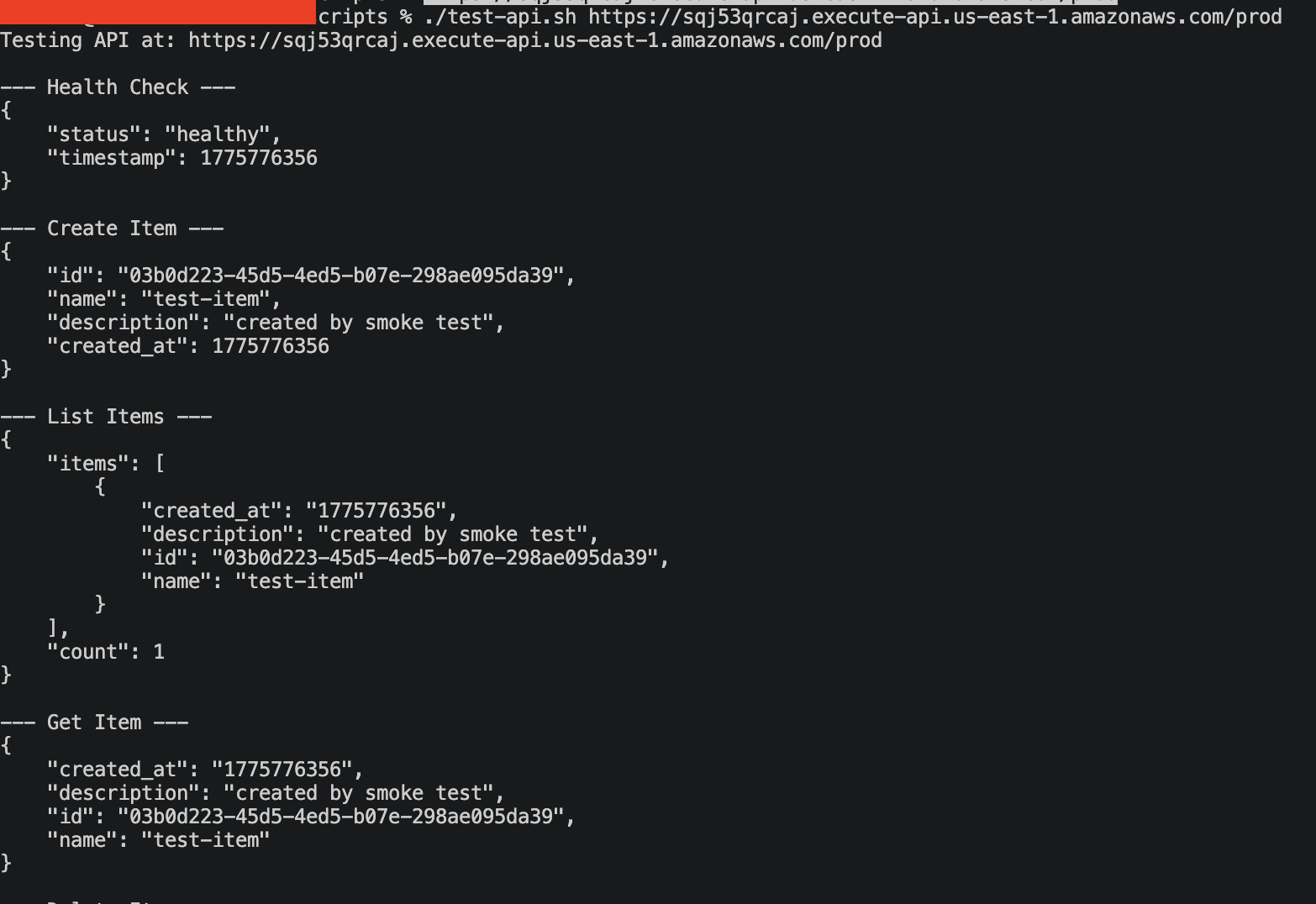
Verifique que a API funciona antes de quebrá-la:
./scripts/test-api.sh https://YOUR-API-ID.execute-api.us-east-1.amazonaws.com/prodO script executa o ciclo CRUD completo: health check, criar item, listar itens, buscar item, deletar item. Todas as chamadas devem retornar 200.
{
"status": "healthy",
"timestamp": 1744214400
}
A função Lambda é um armazenamento simples de itens. Nada sofisticado, apenas o suficiente para gerar métricas no CloudWatch e ficar claramente quebrada quando o DynamoDB parar de cooperar:
def create_item(body):
if not body.get("name"):
return response(400, {"error": "Missing required field: name"})
item = {
"id": str(uuid.uuid4()),
"name": body["name"],
"description": body.get("description", ""),
"created_at": int(time.time()),
}
table.put_item(Item=item)
return response(201, item)Quebrando Tudo: O Script de Starvation de Capacidade
Agora o caos. O script faz duas coisas:
- Muda o DynamoDB de on-demand para provisionado com 1 RCU / 1 WCU. Isso é o equivalente a transformar uma rodovia em uma estrada de terra de faixa única. Qualquer tráfego significativo vai exceder a capacidade.
- Dispara 1.000 requisições POST na API. Cada requisição tenta escrever um item no DynamoDB. Com apenas 1 write capacity unit, a maioria delas vai falhar com
ProvisionedThroughputExceededException. Por que 1.000? O DynamoDB retém 300 segundos de capacidade não utilizada como burst credits, então um burst menor pode ser absorvido sem disparar throttles.
./chaos/capacity-starvation.sh \
https://YOUR-API-ID.execute-api.us-east-1.amazonaws.com/prodA saída do script mostra a progressão:
============================================
CHAOS: DynamoDB Capacity Starvation
============================================
Target API: https://abc123.execute-api.us-east-1.amazonaws.com/prod
Target Table: devops-agent-demo-items
[1/4] Recording current table configuration...
Current billing mode: PAY_PER_REQUEST
[2/4] Switching to PROVISIONED mode with 1 RCU / 1 WCU...
Table is ACTIVE with 1 RCU / 1 WCU
[3/4] Blasting 1000 requests at the API...
Sent 20 / 1000 requests...
Sent 40 / 1000 requests...
...
[4/4] Chaos injection complete.
A saída mostra códigos de status HTTP para cada requisição. Um 201 significa que a escrita foi bem-sucedida, seja pelos burst credits restantes ou pela única WCU provisionada. Um 500 significa que o DynamoDB rejeitou a escrita com ProvisionedThroughputExceededException e a função Lambda retornou um erro interno do servidor. Você pode ver o padrão: majoritariamente 500s com 201s ocasionais passando, já que 1 WCU permite aproximadamente uma escrita bem-sucedida por segundo.
Aqui está o que o script faz por dentro. A parte chave é a chamada aws dynamodb update-table que muda o modo de cobrança:
# Switch to provisioned with minimal capacity
aws dynamodb update-table \
--table-name "$TABLE_NAME" \
--billing-mode PROVISIONED \
--provisioned-throughput ReadCapacityUnits=1,WriteCapacityUnits=1Este é um cenário realista. Auto-scaling mal configurado, uma mudança acidental de capacidade durante um sprint de otimização de custos, ou um Terraform apply que sobrescreve on-demand com configurações provisionadas. Eu já vi tudo isso em produção.
Em um ou dois minutos, a falha em cascata fica visível no console do CloudWatch:
- DynamoDB:
WriteThrottleEventssalta de 0 para dezenas por minuto - Lambda: A função retorna respostas 500 conforme o DynamoDB rejeita escritas com
ProvisionedThroughputExceededException - API Gateway: A contagem de
5XXErrorsobe conforme os 500s se propagam para os clientes
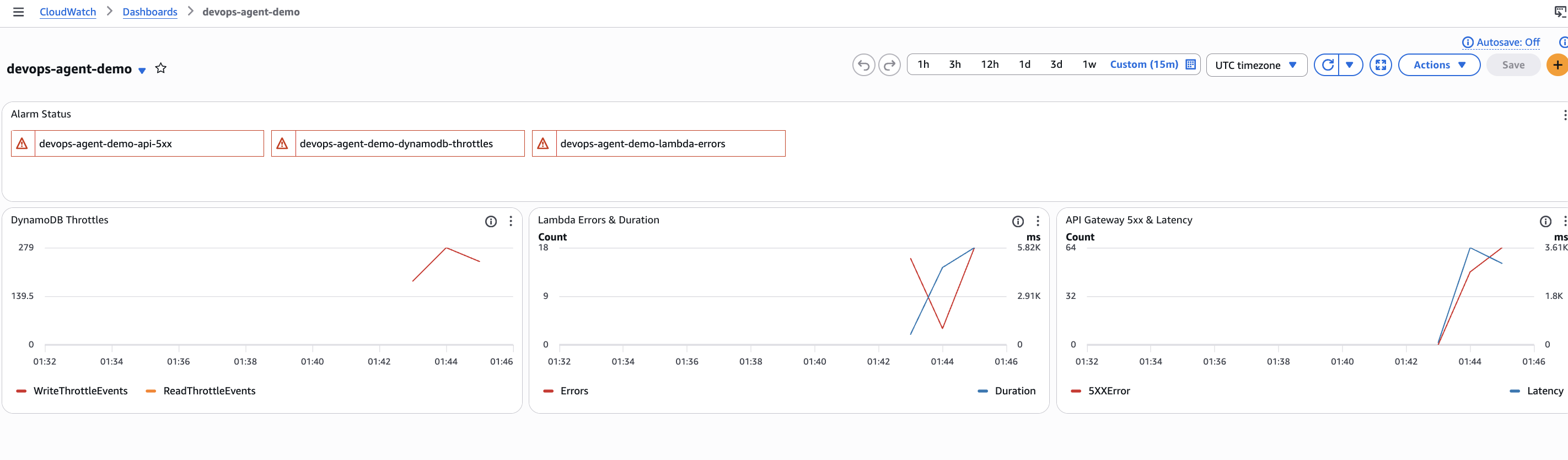
O dashboard conta a história completa. No topo, todos os três alarmes estão em estado ALARM (vermelho). O gráfico DynamoDB Throttles à esquerda mostra um pico acentuado em WriteThrottleEvents, atingindo 279 em um único minuto. O gráfico Lambda Errors & Duration no centro mostra os erros subindo conforme o DynamoDB rejeita escritas, com um salto correspondente na duração da função conforme o SDK faz retries antes de falhar. O gráfico API Gateway 5xx & Latency à direita mostra os erros 5xx chegando aos clientes, com latência disparando conforme as requisições se acumulam atrás das chamadas throttled do DynamoDB.
Este é o padrão de falha em cascata: throttles do DynamoDB se propagam pelo Lambda até o API Gateway, e cada camada adiciona suas próprias métricas de latência e erro. Os alarmes do CloudWatch disparam, e é isso que aciona a investigação do DevOps Agent.
Acionando o DevOps Agent
Existem múltiplas formas de iniciar uma investigação:
- Automática: O DevOps Agent monitora seus alarmes CloudWatch e pode iniciar investigações automaticamente quando alarmes disparam (se configurado).
- Console: No dashboard do Agent Space, clique no botão Operator access no canto superior direito. Isso abre o web app do DevOps Agent onde você pode iniciar investigações e interagir com o agente.
- CLI: Use a AWS CLI para iniciar uma investigação programaticamente.
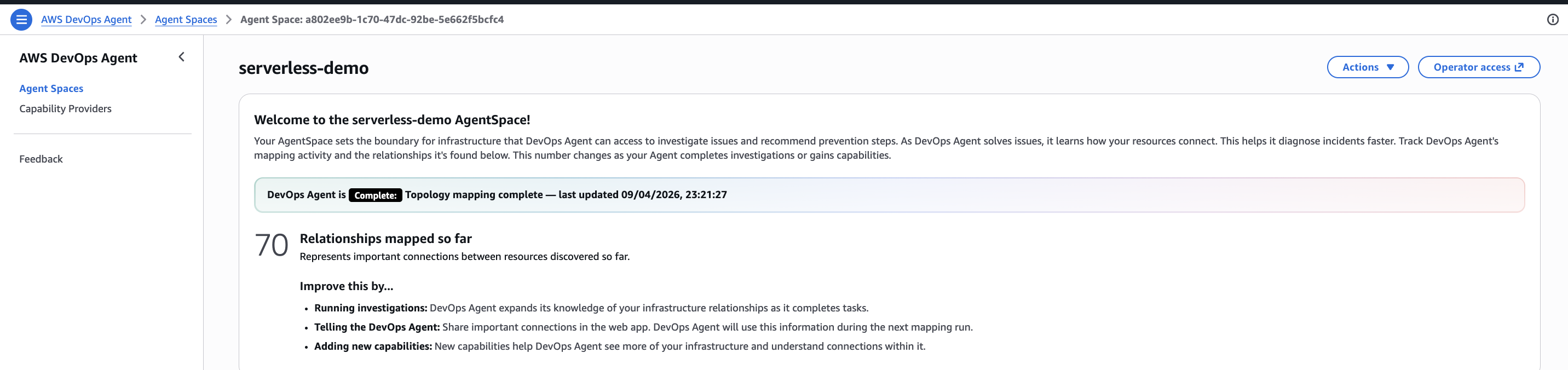
Para esta demo, eu cliquei em Operator access, que abre o Incident Response Dashboard. O painel esquerdo é uma interface de chat onde você pode interagir diretamente com o agente. O painel principal mostra um formulário Start an investigation com prompts sugeridos como “Latest alarm”, “High CPU usage” e “Error rate spike”. Abaixo disso está uma lista de investigações passadas e um gráfico de frequência diária de investigações.
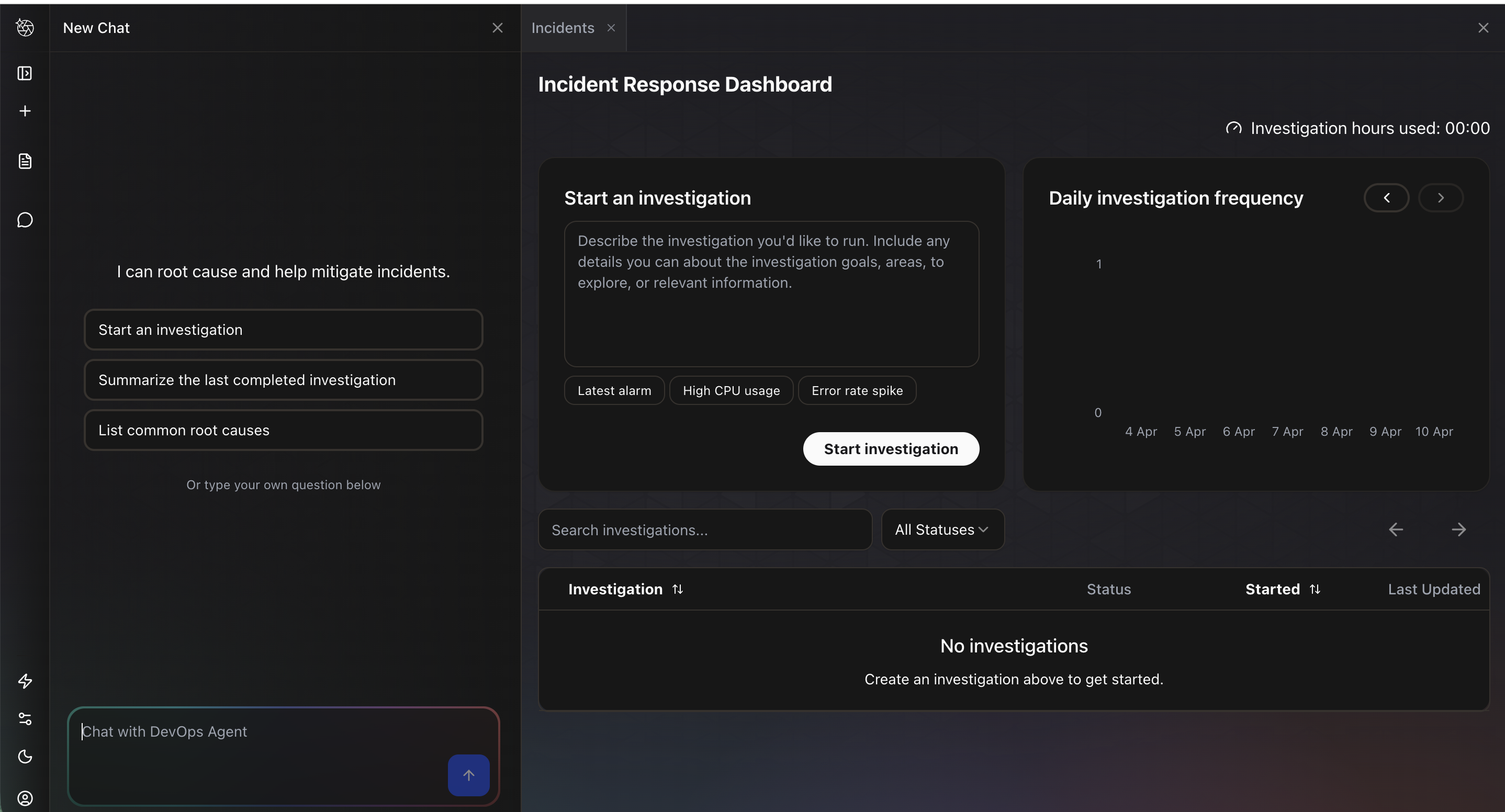
Eu cliquei em Start an investigation, que abre um diálogo com dois campos: Investigation details onde você descreve o problema, e Investigation starting point onde você pode opcionalmente apontar o agente para um alarme, métrica ou trecho de log específico. Eu inseri “Investigate my latest CloudWatch alarm that triggered and analyze the underlying metrics and logs to determine the root cause” e cliquei em Start investigating.
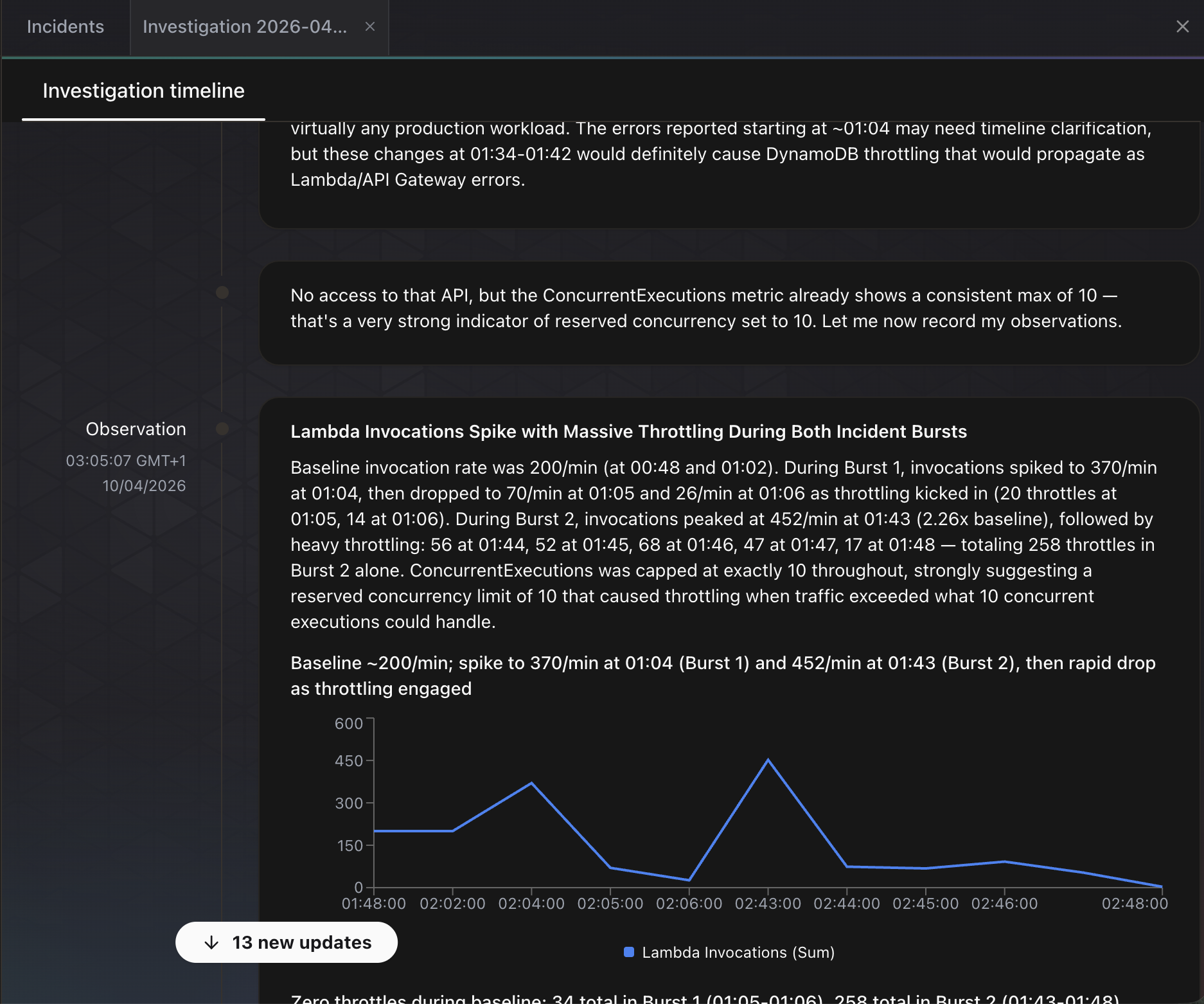
O agente imediatamente começa a trabalhar. A timeline da investigação é atualizada em tempo real conforme ele publica observações. Na captura de tela abaixo, o agente já identificou dois padrões de burst nas invocações do Lambda, notando que as invocações saltaram de uma baseline de 200/min para 370/min e 452/min durante a injeção de caos. Ele identificou que ConcurrentExecutions estava limitado a exatamente 10 ao longo de todo o período, sugerindo um limite de reserved concurrency. Ele também correlacionou o timing do throttling do DynamoDB com os picos de erro do Lambda e observou que essas mudanças “definitivamente causariam throttling no DynamoDB que se propagaria como erros do Lambda/API Gateway.”
O agente até gerou um gráfico inline de invocações do Lambda ao longo do tempo, mostrando os dois bursts de tráfego e a queda subsequente conforme o throttling começou.
O Que o DevOps Agent Encontrou
A investigação levou aproximadamente 6 minutos. Aqui está a análise de causa raiz:
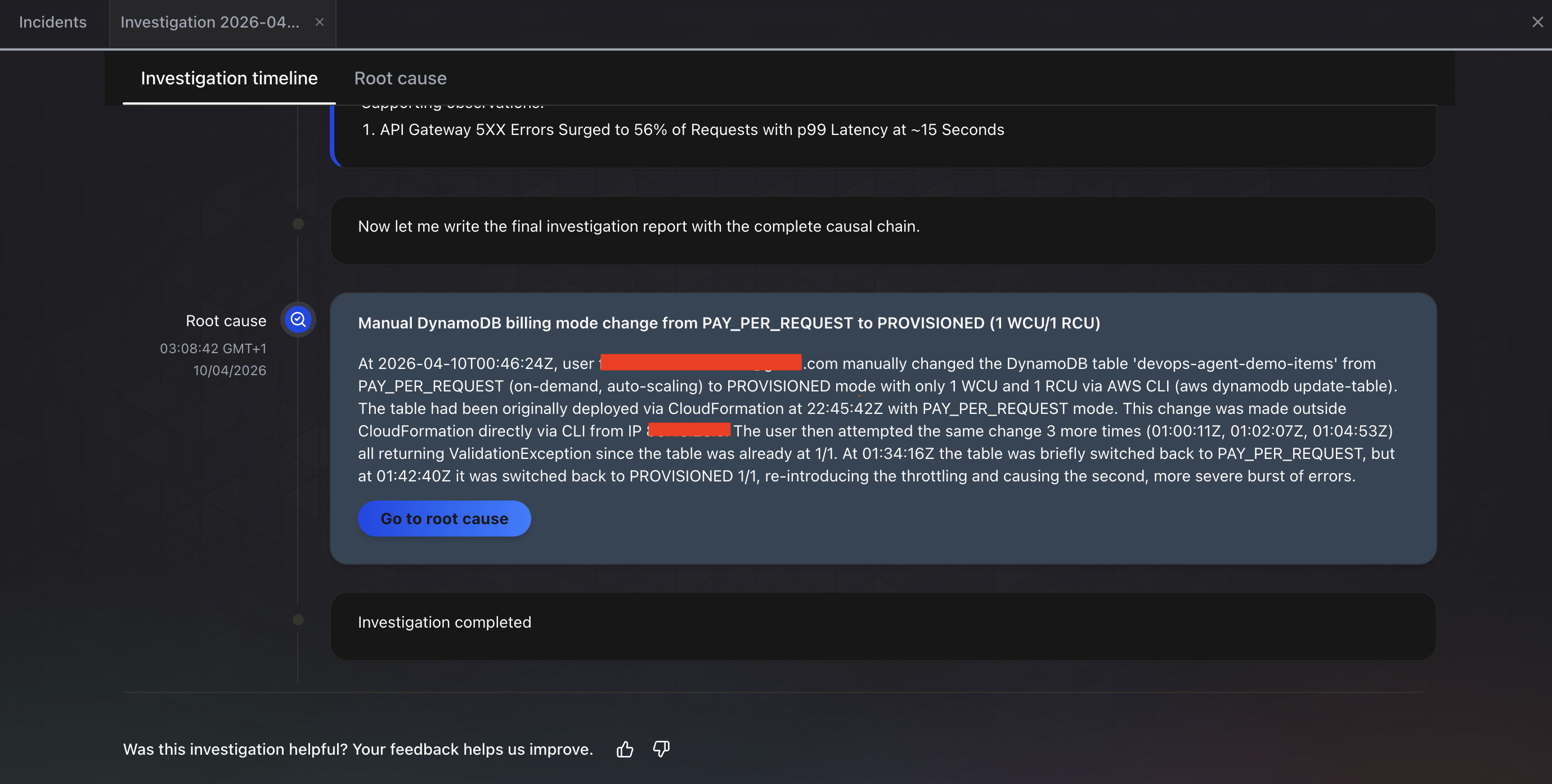
A investigação foi concluída em cerca de 6 minutos. A aba Root cause mostra a descoberta final: “Manual DynamoDB billing mode change from PAY_PER_REQUEST to PROVISIONED (1 WCU/1 RCU).” O agente identificou:
- Causa raiz: Um usuário mudou manualmente a tabela DynamoDB
devops-agent-demo-itemsde PAY_PER_REQUEST (on-demand, auto-scaling) para modo PROVISIONED com apenas 1 WCU e 1 RCU via AWS CLI (aws dynamodb update-table) - Cadeia de impacto: Erros 5xx do API Gateway subiram para 56% das requisições com latência p99 em aproximadamente 15 segundos
- Histórico de configuração: O agente traçou toda a timeline, notando que a tabela foi originalmente implantada via CloudFormation com modo PAY_PER_REQUEST, depois alterada fora do CloudFormation diretamente via CLI
- Múltiplas tentativas detectadas: O agente até percebeu múltiplas chamadas
update-table, algumas retornandoValidationExceptionporque a tabela já estava em 1/1, e que a tabela foi brevemente revertida para PAY_PER_REQUEST antes de ser configurada novamente para PROVISIONED, reintroduzindo o throttling
A aba Mitigation plan vai além. Ela fornece um plano de remediação passo a passo, começando com “Step 1: Prepare” para verificar a configuração atual da tabela antes de fazer mudanças. Ela até fornece o comando CLI exato para executar: aws dynamodb describe-table --table-name devops-agent-demo-items --region us-east-1. A recomendação é reverter a tabela de PROVISIONED (1 WCU/1 RCU) de volta para PAY_PER_REQUEST para restaurar o escalonamento automático de capacidade. Ela nota que o template CloudFormation originalmente especificava o modo PAY_PER_REQUEST, então esta mitigação reverte a mudança manual de configuração para restaurar a configuração pretendida pelo template.
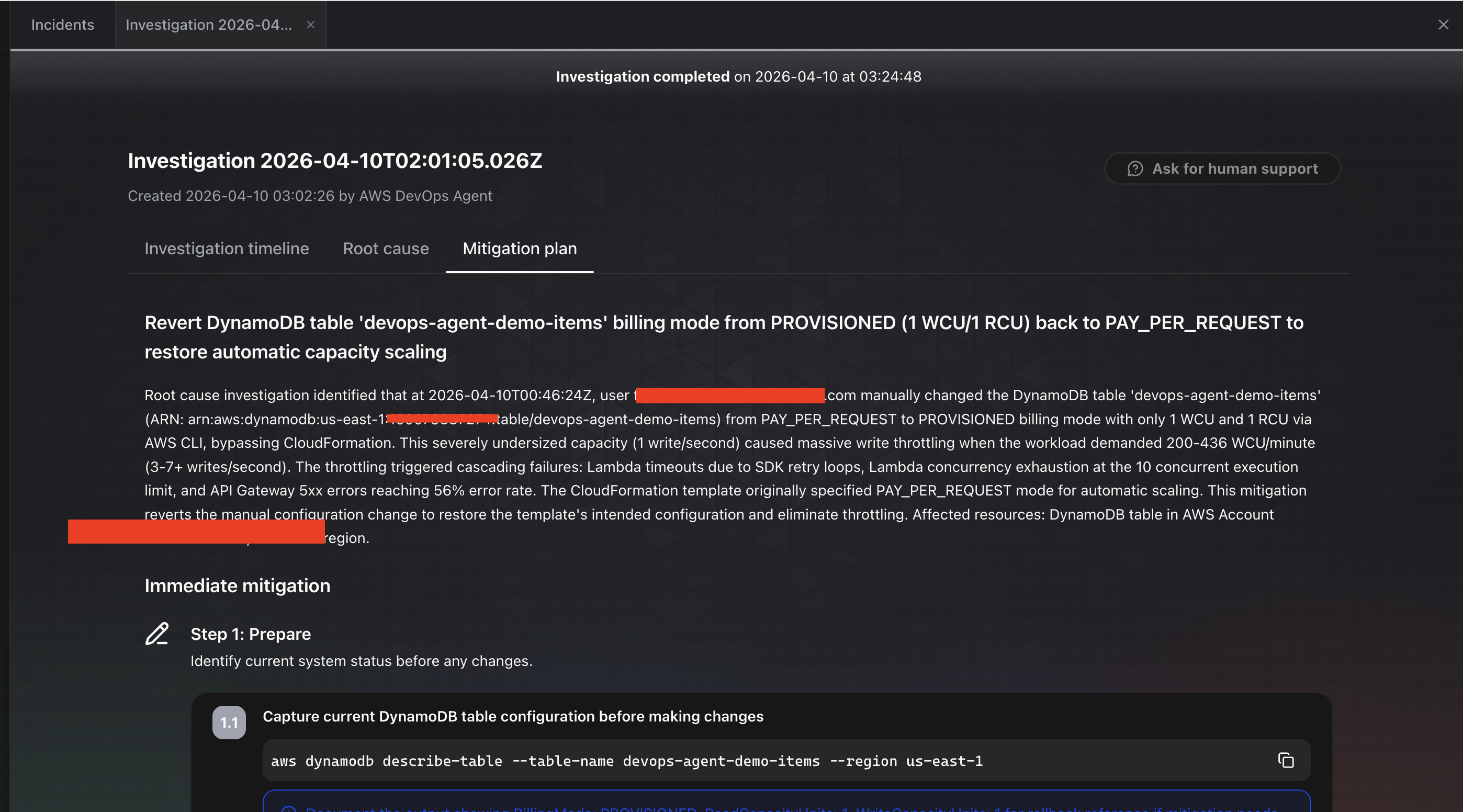
Isso é exatamente o que aconteceu. O agente rastreou toda a cadeia corretamente: erros da API para falhas do Lambda, para throttling do DynamoDB, até uma mudança manual do modo de cobrança feita via CLI. Ele não identificou apenas o sintoma (erros). Ele identificou a causa raiz (uma mudança de configuração feita fora do CloudFormation), explicou a cadeia completa de impacto (throttling causou falhas no Lambda, loops de retry do SDK, esgotamento de concorrência e taxa de erro 5xx de 56% no API Gateway), e recomendou a correção específica com comandos executáveis.
Restaurando a Tabela
Após a investigação, restaure a tabela DynamoDB:
./chaos/restore.shIsso muda a tabela de volta para o modo de cobrança on-demand. Os alarmes devem ser resolvidos em alguns minutos conforme a fila de requisições throttled é drenada.
Custo da Investigação
A investigação rodou por aproximadamente 6 minutos, ou 360 agent-seconds.
Custo: 360 x $0.0083 = $2.99
Mais um valor pequeno para queries do CloudWatch Logs Insights durante a investigação. Custo total para esta demo: menos de $4.
Para comparação, investigar este problema manualmente envolveria:
- Abrir o CloudWatch, verificar quais alarmes dispararam (2 minutos)
- Navegar até o console do DynamoDB, verificar métricas da tabela (3 minutos)
- Verificar os logs da função Lambda para padrões de erro (5 minutos)
- Verificar a configuração da tabela DynamoDB para identificar a mudança de capacidade (3 minutos)
- Correlacionar a timeline da mudança de capacidade com o início dos erros (5 minutos)
Um SRE experiente conseguiria fazer isso em cerca de 15 a 20 minutos. Um engenheiro menos experiente poderia levar 45 minutos ou mais, especialmente se não pensar imediatamente em verificar a configuração de cobrança do DynamoDB. O DevOps Agent fez isso em 6 minutos por $3.
Preços
O DevOps Agent cobra $0.0083 por agent-second em todas as atividades: investigações, avaliações e chat. Isso equivale a aproximadamente $0.50 por minuto ou $29.88 por hora de trabalho ativo do agente. Você só paga pela computação ativa, não pelo tempo ocioso.
Aqui está o que investigações reais custam na prática:
| Cenário | Duração | Custo |
|---|---|---|
| Investigação rápida (throttling DynamoDB) | ~6 minutos | ~$3.00 |
| Investigação moderada (multi-serviço) | ~10 minutos | ~$5.00 |
| Investigação complexa (cross-account) | ~30 minutos | ~$14.94 |
| Mensal: time pequeno, 10 investigações | ~80 minutos no total | ~$40 |
| Mensal: time ativo, 80 investigações + chat | ~19 horas no total | ~$568 |
Para comparação, uma investigação manual de P1 por um SRE normalmente leva 45 a 60 minutos. Com um custo total de SRE de $150.000/ano, isso dá aproximadamente $75 por hora de tempo de engenharia. Uma investigação de 6 minutos pelo DevOps Agent a $3 é uma economia significativa, se o diagnóstico for preciso.
Trial Gratuito
Novos clientes recebem um trial gratuito de 2 meses a partir da primeira tarefa operacional:
- Até 10 Agent Spaces
- 20 horas de investigações por mês
- 15 horas de avaliações por mês
- 20 horas de tarefas SRE on-demand por mês
Isso é mais que suficiente para executar esta demo e avaliar a ferramenta completamente.
Créditos do AWS Support
É aqui que os preços ficam interessantes para clientes AWS existentes. Suas cobranças mensais do AWS Support se convertem em créditos do DevOps Agent:
| Plano de Suporte | Percentual de Crédito |
|---|---|
| Unified Operations | 100% |
| Enterprise Support | 75% |
| Business Support+ | 30% |
Se sua conta do Enterprise Support é de $5.000/mês, você recebe $3.750 em créditos do DevOps Agent. Isso cobre uso significativo antes de pagar qualquer valor adicional. Os créditos expiram mensalmente se não utilizados.
Custos Ocultos
A taxa por agent-second não é o quadro completo. O DevOps Agent faz queries no CloudWatch Logs Insights, recupera traces e lê métricas durante investigações. Essas chamadas de serviço AWS subjacentes são cobradas nas taxas padrão. Para um workload serverless com volume modesto de logs, o custo adicional é desprezível. Para um ambiente grande com terabytes de logs, isso pode se acumular. É algo para monitorar no primeiro mês.
Veredito
O Que Funciona
A precisão da causa raiz foi impressionante. No meu teste, o agente rastreou corretamente erros 5xx do API Gateway através do Lambda até o throttling do DynamoDB, e identificou a mudança de configuração específica que causou o problema. A AWS reporta 94% de precisão na identificação de causa raiz de clientes do preview. Eu não consigo verificar esse número em todos os cenários, mas para este workload serverless, ele acertou o diagnóstico.
O tempo até o diagnóstico é genuinamente rápido. Seis minutos do início da investigação até a causa raiz, incluindo queries de logs, análise de métricas e detecção de mudanças. O agente não apenas apontou para o sintoma (“DynamoDB está com throttling”). Ele conectou os pontos até a mudança de modo de cobrança que causou o throttling.
O setup é mínimo. Quinze minutos para criar um Agent Space, criar automaticamente a IAM role e começar a investigar. Sem agentes para instalar, sem sidecars, sem arquivos de configuração. Se você já usa CloudWatch, o DevOps Agent funciona pronto para uso.
Os preços são diretos. Pay-per-second sem cobranças por ociosidade. Uma investigação típica custa de $3 a $5. O offset de créditos do AWS Support o torna efetivamente gratuito para muitos clientes Enterprise.
O Que Não Funciona
Sem auto-remediação. O agente diz o que fazer, mas não pode executar. Para minha demo, a correção era uma única linha (aws dynamodb update-table --billing-mode PAY_PER_REQUEST). Ter o agente simplesmente executando isso, com aprovação, seria mais útil. A AWS diz que remediação autônoma pode vir “quando a confiança for alta o suficiente”, mas hoje é apenas recomendação.
Lacunas na investigação são reais. O blog de melhores práticas avisa que “haverá muitas investigações que o agente não consegue continuar” devido a contexto, telemetria ou permissões insuficientes. Se seus logs são esparsos ou suas permissões IAM muito restritas, o agente vai reportar lacunas em vez de respostas. Isso é honesto e transparente, mas significa que a ferramenta é tão boa quanto seu setup de observabilidade.
Regiões limitadas. Seis regiões no GA. Se seus workloads principais rodam em ap-southeast-1 (Singapura) ou sa-east-1 (São Paulo), você não pode usar ainda. O agente pode monitorar recursos em qualquer região a partir de uma região home suportada, mas o Agent Space em si deve residir em uma das seis.
Engajamento da comunidade é baixo. Eu não encontrei nenhuma thread substancial no Reddit e quase zero discussão no Hacker News sobre esta ferramenta. A maioria do conteúdo existente é escrito por AWS Community Builders. Avaliações independentes e críticas são escassas. Isso pode significar que a ferramenta ainda não alcançou a comunidade mais ampla de desenvolvedores, ou que ela resolve um problema que apenas times maiores com rotações de on-call sentem agudamente.
Como Se Compara
DevOps Agent não é um substituto para Datadog, Dynatrace ou PagerDuty. Ele se integra com todos eles. O modelo mental correto é: essas ferramentas coletam dados e alertam você; o DevOps Agent raciocina sobre os dados e diz por quê.
| Ferramenta | O Que Faz | Auto-Remediação | Modelo de Preços |
|---|---|---|---|
| AWS DevOps Agent | Investigação autônoma e análise de causa raiz | Não (recomenda) | $0.0083/agent-second |
| PagerDuty AIOps | Roteamento de alertas e redução de ruído | Não | $699-799/mês + por usuário |
| Datadog Watchdog | Detecção de anomalias (passiva) | Via Workflow Automation | Incluído no Datadog |
| Dynatrace Davis | Análise causal de causa raiz | Sim (self-healing) | Preços enterprise (cotação) |
Dynatrace Davis é o competidor mais próximo em termos de profundidade. Ele oferece análise causal determinística com workflows de self-healing. Mas exige comprometimento total com a plataforma e preços de nível enterprise. O DevOps Agent é mais leve: você pode adicioná-lo ao seu setup CloudWatch existente em 15 minutos e pagar por investigação.
Datadog Watchdog é uma camada de inteligência passiva. Ele mostra anomalias, mas não investiga autonomamente. Você ainda precisa clicar pelos dashboards e conectar os pontos sozinho. O DevOps Agent faz a conexão por você.
PagerDuty é uma plataforma de gerenciamento de incidentes, não uma ferramenta de investigação. Seu SRE Agent (EA esperado no Q2 2026) vai adicionar capacidades de diagnóstico, mas hoje o PagerDuty gerencia o ciclo de vida do incidente enquanto o DevOps Agent faz a análise.
Quem Deve Usar
Sim: Times rodando workloads significativos na AWS com rotações de on-call. Se você gasta mais de 10 horas por mês em investigação de incidentes, a conta fecha. Clientes Enterprise Support recebem 75% de suas cobranças de suporte como créditos do DevOps Agent, tornando-o efetivamente incluído.
Talvez: Times pequenos com arquiteturas simples. Se você tem 3 funções Lambda e raramente recebe alertas, o trial gratuito vale a pena tentar, mas talvez você não precise de um agente de investigação always-on.
Ainda não: Times primariamente no GCP. O DevOps Agent suporta AWS e Azure, mas não Google Cloud. Times em regiões não suportadas devem aguardar a expansão.
O Quadro Geral
O que mais me chamou atenção é que o DevOps Agent não está tentando substituir seu stack de monitoramento. Ele fica por cima do que você já tem (CloudWatch, Datadog, Dynatrace, Splunk) e adiciona raciocínio. É a camada entre “algo está errado” e “aqui está especificamente o porquê e como corrigir.” Esse posicionamento é inteligente porque não exige arrancar ferramentas existentes. O risco é baixo porque você pode avaliá-lo em um único incidente antes de se comprometer.
A alegação de 94% de precisão da AWS é difícil de verificar independentemente. Eu obtive um diagnóstico correto no meu teste, mas foi um cenário limpo com uma única causa raiz clara. Incidentes reais de produção são mais confusos: múltiplas coisas quebram simultaneamente, logs são incompletos e a causa raiz pode abranger serviços de times diferentes. Como o agente lida com esses cenários é o verdadeiro teste, e ninguém publicou benchmarks independentes ainda.
Por $3 por investigação, vale a pena experimentar no seu próximo incidente e comparar a análise do agente com o que seu time encontra manualmente. Se ele economizar 30 minutos de tempo de SRE mesmo na metade das vezes, ele se paga.
Limpando Tudo
Quando terminar com a demo, delete tudo:
./scripts/cleanup.sh devops-agent-demo us-east-1Isso remove o stack CloudFormation e todos os seus recursos. Você também pode deletar o Agent Space pelo console do DevOps Agent se não precisar mais dele.